Hi, this is Wei Huang(黄炜)’s website!
I am currently a Ph.D in HKU, supervised by Prof.Xiaojuan Qi, Prof.Shiming Zhang. I am also co-supervised by Prof.Zhongrui Wang.
I obtained my bachelor’s degree in Jun 2023, supervised by Prof.Si Liu.
NVIDIA Research Intern -- Efficient AI Group
I am a core author of Long-RL, LongLive 1.0, LongLive 2.0, and Tri-Attention, and a core contributor to Nemotron 3 Nano Omni.
Main/core open-source contributions with 6K+ GitHub stars in total.
I focus on efficient and tiny deep learning for lightweight, long-sequence, and fast AI, spanning:
🚀 Compression: low-bit quantization, pruning, and sparsity for LLMs, VLMs, and diffusion models.
🧠 Reasoning: efficient RL and long-sequence reasoning for LLMs/VLMs.
🎬 Generation: real-time and interactive long-video generation.
⌚ Wearable AI: edge AI and OECT-based sensing.
🔥 Brain-Mimic Computing: neuromorphic computing and hardware acceleration.
🔥 News
- 2026.06: 🎉🎉 One paper (Anchor Forcing) is accepted by ECCV’26!
- 2026.05: 🎉🎉 Two papers are accepted by ICML’26! One for efficent long context compression (Tri-Attention) and one for diffusion quantization (Absorbing Quantization Error).
- 2026.02: 🎉🎉 One paper for 4D Vision-language Models (Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models) is accepted by CVPR’26! All the codes are opensourced now!
- 2026.02: 🎉🎉 One paper for extreme MoE-LLMs/VLMs compression (MC#: Mixture Compressor for Mixture-of-Experts Large Models) is accepted by IEEE TPAMI, Top Journal, IF=20.4!
- 2026.01: 🎉🎉 Three papers are accepted by ICLR’26! One for Low-bit LLM RL (QeRL: NVFP4 training for parameter-efficient RL) and two papers (LongLive: streaming interactive long-video generation; OmniVinci: a foundation model for omni-LLM) for long-video generation and foundation omni-LLMs. All the codes are opensourced now!
- 2025.10: 🎉🎉 One paper for wearable AI guided glucose management (A Wearable, Dual Closed-loop Insulin Delivery System for Precision Diabetes Management) is accepted by Advanced Materials, Top Interdisciplinary Journal, IF=26.8!
- 2025.09: 🎉🎉 Two papers are accepted by Neurips’25! One for scaling long-video reasoning (Long-RL: Scaling RL to Long Videos) and one for unified reasoning model (Mindomni: Unleashing reasoning generation in vision language models with rgpo). All the codes are opensourced now!
- 2025.05: 🎉🎉 One paper for structural mixed-precision low-bit quantization for LLMs (SliM-LLM) is accepted by ICML’25! All the codes are opensourced now!
- 2025.02: 🎉🎉 One paper for efficient fine-grained chain-of-thought video understanding framework (VideoEspresso) is accepted by CVPR’25, Oral Paper 0.73%! All the codes are opensourced now!
- 2025.01: 🎉🎉 Three papers are accepted by ICLR’25! One for MoE-LLM compression (MC-MoE: MoE-LLM compression) and two papers (InfoMax: data pruning; From-Layers-to-States: dynamic neural network layer) for data efficiency and dynamic neural networks. All the codes are opensourced now!
- 2024.12: 🎉🎉 One Technical Report is accepted by Visual Intelligence
- 2024.05: 🎉🎉 One paper for snn security on rram is accepted by ICCAD’24! All the codes are opensourced now!
- 2024.04: 🎉🎉 One paper for post-training binary quantization of LLMs is accepted by ICML’24! All the codes are opensourced now!
💬 Invited Talks and Report
- 2026.05: Our TriAttention was reported by 新智元. Please see the link.
- 2025.11: 青稞社区 online talk on QeRL. Please see the video.
- 2025.10: Our OmniVinci was reported by 机器之心,Sina(新浪财经). Please see the link.
- 2025.10: Our LongLive was reported by 新智元. Please see the link.
- 2025.07: Our Scaling RL to Long Videos was reported by 机器之心. Please see the link.
- 2025.06: AI-Time online talk on VideoEspresso. Please see the video.
- 2024.05: BiLLM was reported by IEEE Spectrum. Thanks to Matthew for the interview and report. Please see the link.
- 2024.05: AI-Time online talk on BiLLM. Please see the video.
- 2024.04: Our emperical study How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study (new version: An Empirical Study of LLaMA3 Quantization: From LLMs to MLLMs) was reported by QbitAI (量子位). Please see the link.
- 2024.03: Our BiLLM: Pushing the Limit of Post-Training Quantization for LLMs was reported by QbitAI (量子位). Please see the link.
📝 Publications
Under Review

LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation 
Yukang Chen*, Luozhou Wang*, Wei Huang*, Shuai Yang*, Bohan Zhang, Yicheng Xiao, Ruihang Chu, Weian Mao, Qixin Hu, Shaoteng Liu, Yuyang Zhao, Huizi Mao, Ying-Cong Chen, Enze Xie, Xiaojuan Qi, Song Han
- End-to-end NVFP4 parallel infrastructure for long-video generation training and inference.
- Balanced sequence parallel AR training with NVFP4 reduces memory cost and accelerates long-video training.
- W4A4 inference, NVFP4 KV cache, parallel dequantization, and asynchronous VAE decoding enable efficient long-video generation.
Paper
Code
Project
Abstract
We present LongLive-2.0, an NVFP4-based parallel infrastructure for the full training and inference workflow of long video generation. For training, LongLive-2.0 introduces Balanced SP for sequence-parallel autoregressive training and combines it with NVFP4 precision to reduce memory cost and accelerate computation. For inference, LongLive-2.0 enables W4A4 NVFP4 execution, NVFP4 KV cache, parallel dequantization, and asynchronous streaming VAE decoding to improve end-to-end throughput. Experiments show up to 2.15x training speedup and 1.84x inference speedup, with LongLive-2.0-5B reaching 45.7 FPS while maintaining strong benchmark performance.
Tech Report
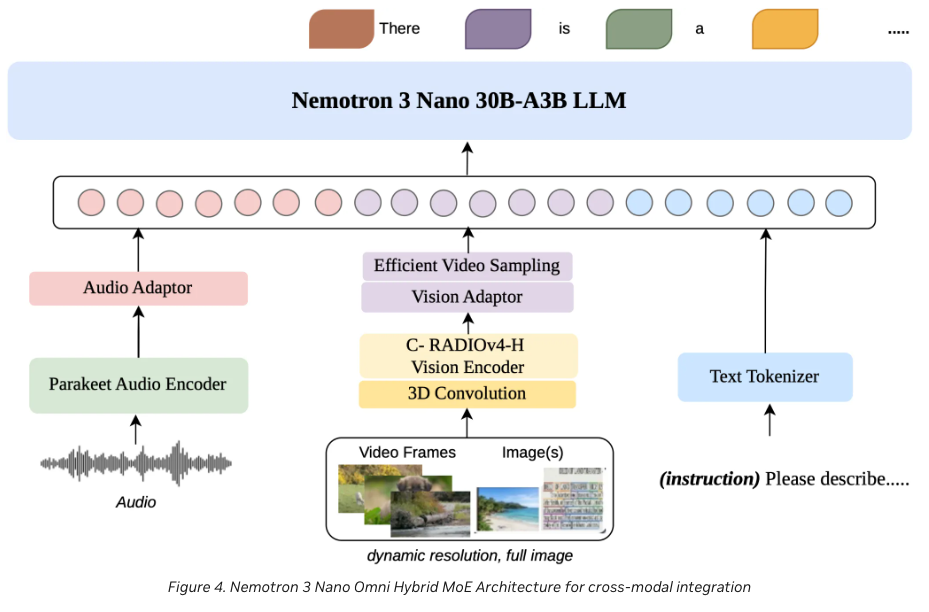
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence 
NVIDIA, including Wei Huang, et al.
- 30B-A3B hybrid Mamba-Transformer MoE for efficient multimodal intelligence.
- Native support for text, image, video, and audio in a unified model.
- Open model checkpoints, training recipes, datasets, and codebase for research and development.
Paper
Code
Model
Abstract
We introduce Nemotron 3 Nano Omni, an efficient open multimodal model with native support for text, image, video, and audio. Built on the Nemotron 3 Nano 30B-A3B backbone, the model incorporates multimodal token-reduction techniques for lower inference latency and higher throughput while improving document understanding, long audio-video comprehension, and agentic computer use. The release includes model checkpoints, training recipes, portions of training data, and code to support further research and development.
ICML 2026
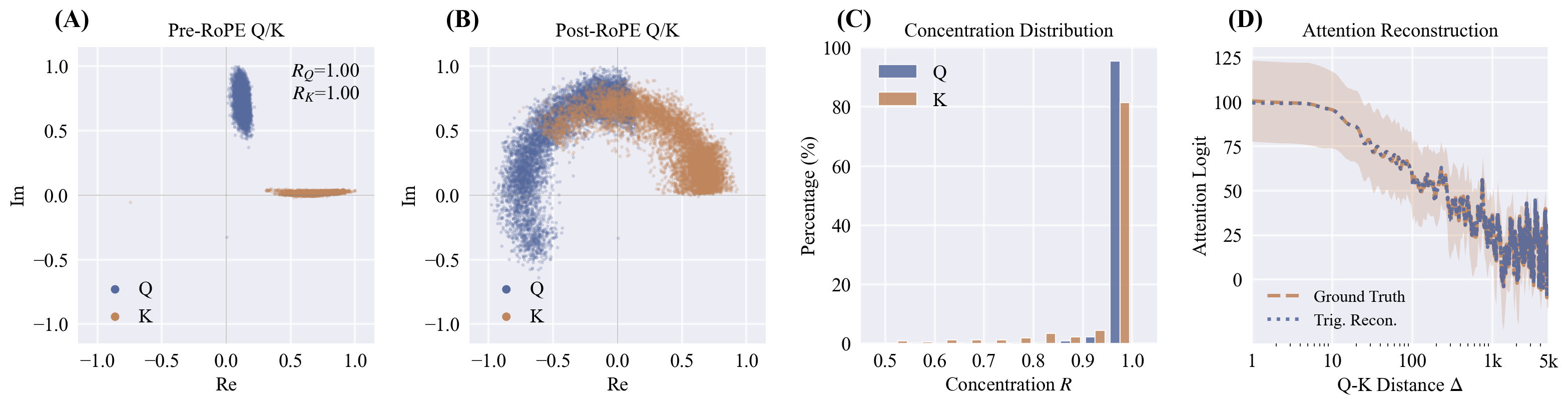
TriAttention: Efficient Long Reasoning with Trigonometric KV Compression 
Weian Mao*, Xi Lin*, Wei Huang*, Yuxin Xie, Tianfu Fu, Bohan Zhuang, Song Han, Yukang Chen
- 2.5x throughput on AIME25 long reasoning while matching Full Attention accuracy (40.8 vs 40.8)
- 10.7x KV memory reduction with trigonometric frequency-domain compression
- OpenClaw compatible — enables local deployment on 24GB RTX 4090
Paper
Code
Abstract
Extended reasoning in large language models (LLMs) creates severe KV cache memory bottlenecks. Leading KV cache compression methods estimate KV importance using attention scores from recent post-RoPE queries. However, queries rotate with position during RoPE, making representative queries very few, leading to poor top-key selection and unstable reasoning. To avoid this issue, we turn to the pre-RoPE space, where we observe that Q and K vectors are highly concentrated around fixed non-zero centers and remain stable across positions -- Q/K concentration. We show that this concentration causes queries to preferentially attend to keys at specific distances (e.g., nearest keys), with the centers determining which distances are preferred via a trigonometric series. Based on this, we propose TriAttention to estimate key importance by leveraging these centers. Via the trigonometric series, we use the distance preference characterized by these centers to score keys according to their positions, and also leverage Q/K norms as an additional signal for importance estimation. On AIME25 with 32K-token generation, TriAttention matches Full Attention reasoning accuracy while achieving 2.5x higher throughput or 10.7x KV memory reduction, whereas leading baselines achieve only about half the accuracy at the same efficiency. TriAttention enables OpenClaw deployment on a single consumer GPU, where long context would otherwise cause out-of-memory with Full Attention.
IEEE TPAMIJournal IF=20.4
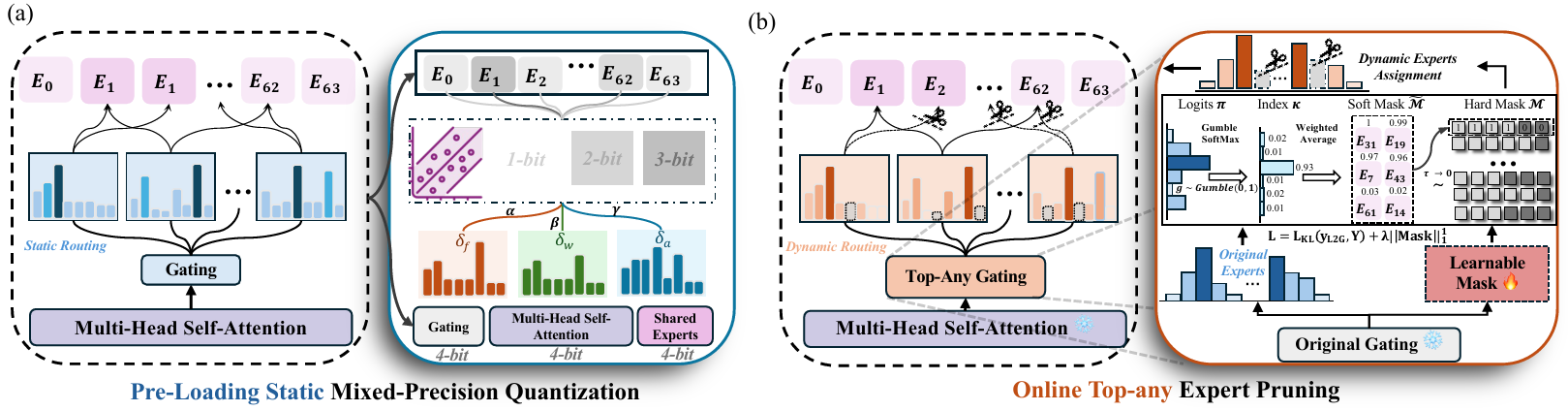
MC#: Mixture Compressor for Mixture-of-Experts Large Models 
Wei Huang, Yue Liao, Yukang Chen, Jianhui Liu, Si Liu, Shiming Zhang, Shuicheng Yan, Xiaojuan Qi
- Accurate weight-only quantization (Weight=1.5~2.5bit) for both MoE-LLMs and MoE-VLMs
- Online Top-any Pruning (OTP) uses Gumbel-Softmax sampling to dynamically select a subset of experts per token
- On DeepSeek-VL2, MC# achieves a 6.2 times weight reduction at 2.57 average bits with only a 1.7% accuracy drop across five multimodal benchmarks. Additionally, OTP reduces expert activation over 20% with less than 1% performance degradation, demonstrating strong potential for efficient MoE-based model deployment.
Paper
Code
Abstract
Mixture-of-Experts (MoE) effectively scales large language models (LLMs) and vision-language models (VLMs) by increasing capacity through sparse activation. However, preloading all experts into memory and activating multiple experts per input introduces significant computational and memory overhead, making the expert module a major contributor to model size and inference cost. To address this, we propose MC# (Mixture-Compressor-sharp), a framework that combines static quantization and dynamic expert pruning by leveraging the significance of experts and tokens for aggressive compression of MoE-LLMs/VLMs. To reduce storage and loading costs, we introduce Pre-Loading Mixed-Precision Quantization (PMQ), which optimizes bit allocation via linear programming, balancing expert importance and quantization error for a Pareto-optimal trade-off between size and performance. To reduce runtime computation, Online Top-any Pruning (OTP) uses Gumbel-Softmax sampling to dynamically select a subset of experts per token, enabling fine-grained control over activation. By combining PMQ's static bit-width optimization with OTP's dynamic routing, MC# achieves extreme compression with minimal accuracy loss. On DeepSeek-VL2, MC# achieves a 6.2 times weight reduction at 2.57 average bits with only a 1.7% accuracy drop across five multimodal benchmarks. Additionally, OTP reduces expert activation over 20% with less than 1% performance degradation, demonstrating strong potential for efficient MoE-based model deployment.
ICLR 2026
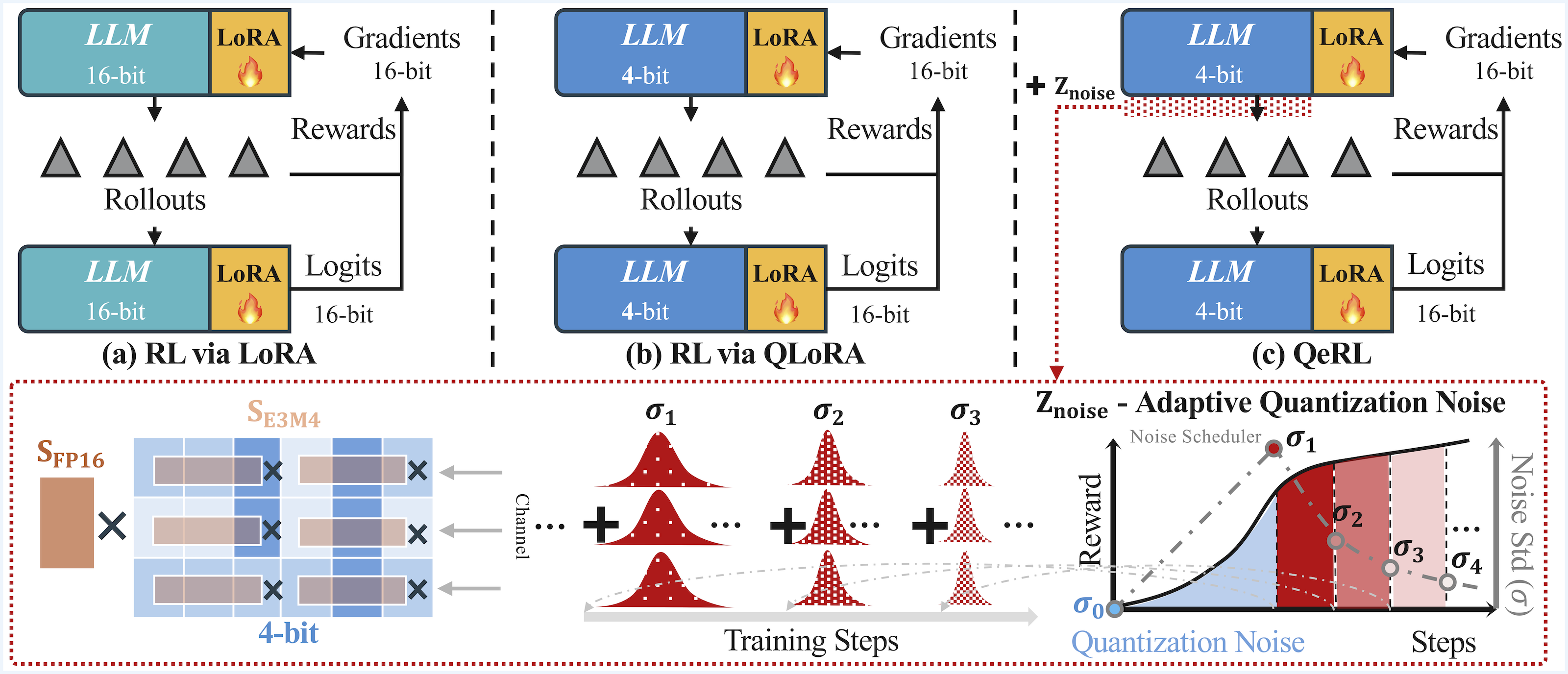
QeRL: Beyond Efficiency – Quantization-enhanced Reinforcement Learning for LLMs 
Wei Huang, Yi Ge, Shuai Yang, Yicheng Xiao, Huizi Mao, Yujun Lin, Hanrong Ye, Sifei Liu, Ka Chun Cheung, Hongxu Yin, Yao Lu, Xiaojuan Qi, Song Han, Yukang Chen
- 🧠 4-bit quantized RL training.
- 💪 Train a 32B LLM on a single H100 GPU.
- 🎯 Accuracy on par with bfloat16-level accuracy.
- 🔥 Supports NVFP4 quantization format.
Paper
Code
Abstract
We propose QeRL, a Quantization-enhanced Reinforcement Learning framework for large language models (LLMs). While RL is essential for LLMs' reasoning capabilities, it is resource-intensive, requiring substantial GPU memory and long rollout durations. QeRL addresses these issues by combining NVFP4 quantization with Low-Rank Adaptation (LoRA), accelerating rollout phase of RL while reducing memory overhead. Beyond efficiency, our findings show that quantization noise increases policy entropy, enhancing exploration, and enabling the discovery of better strategies during RL. To further optimize exploration, QeRL introduces an Adaptive Quantization Noise (AQN) mechanism, which dynamically adjusts noise during training. Experiments demonstrate that QeRL delivers over 1.5 times speedup in the rollout phase. Moreover, this is the first framework to enable RL training of a 32B LLM on a single H100 80GB GPU, while delivering overall speedups for RL training. It also achieves faster reward growth and higher final accuracy than 16-bit LoRA and QLoRA, while matching the performance of full-parameter fine-tuning on mathematical benchmarks such as GSM8K (90.8%) and MATH 500 (77.4%) in the 7B model. These results establish QeRL as an efficient and effective framework for RL training in LLMs.
ICLR 2026

LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, Yukang Chen
- Generates video in real time as users enter text prompts.
- 20.7 FPS on a single H100, up to 240s per clip. Fine-tunes SOTA short-video models (e.g., Wan) into long-video generators.
- One step closer to World Models.
Paper
Code
Abstract
We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
ICLR 2026
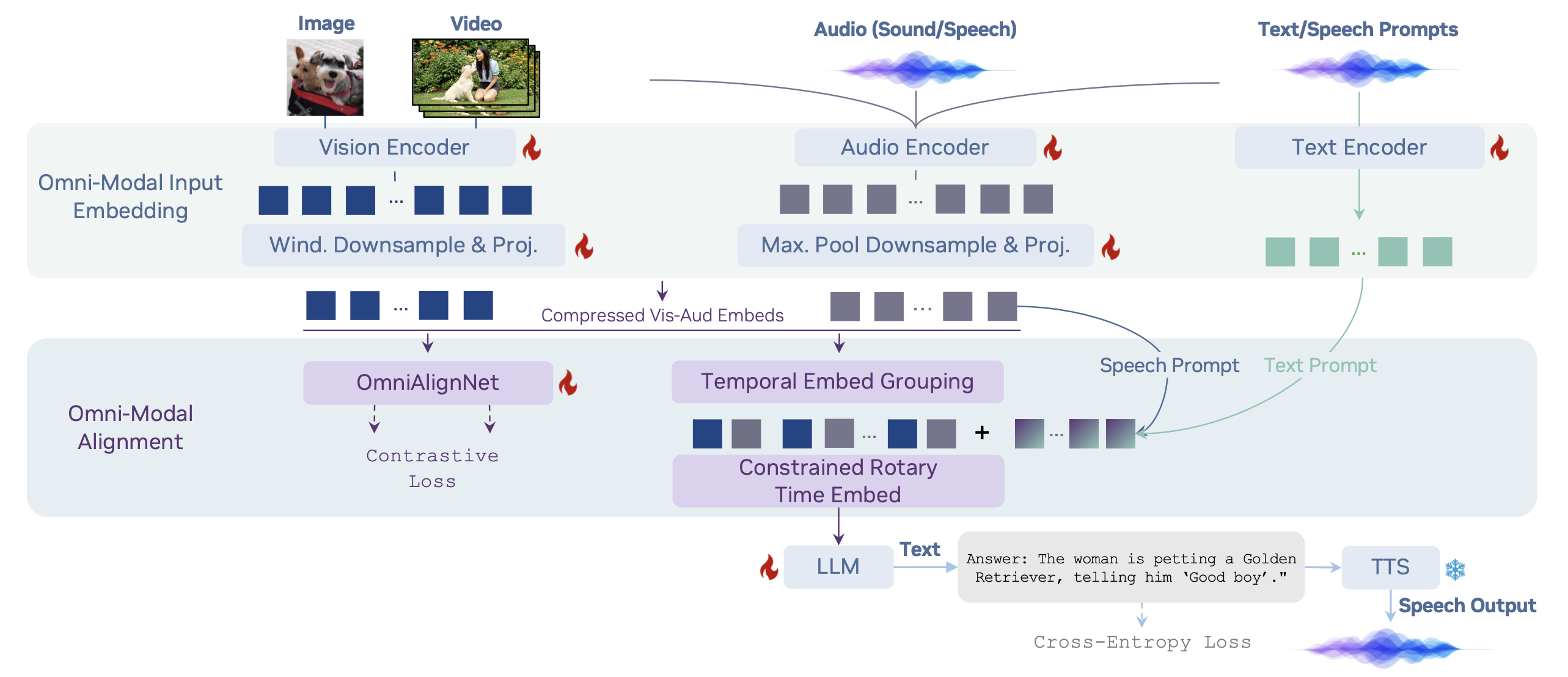
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM 
Hanrong Ye*, Chao-Han Huck Yang*, Arushi Goel*,Wei Huang*, Ligeng Zhu*, Yuanhang Su*, Sean Lin*, An-Chieh Cheng*, Zhen Wan*, Jinchuan Tian*, Yuming Lou*, Dong Yang*, Zhijian Liu, Yukang Chen, Ambrish Dantrey, Ehsan Jahangiri, Sreyan Ghosh, Daguang Xu, Ehsan Hosseini Asl, Danial Mohseni Taheri, Vidya Murali, Sifei Liu, Yao Lu, Oluwatobi Olabiyi, Yu-Chiang Frank Wang, Rafael Valle, Bryan Catanzaro, Andrew Tao, Song Han, Jan Kautz, Hongxu Yin*, Pavlo Molchanov*
- OmniAlignNet for strengthening alignment between vision and audio embeddings in a shared omni-modal latent space.
- emporal Embedding Grouping for capturing relative temporal alignment between vision and audio signals.
- Constrained Rotary Time Embedding for encoding absolute temporal information in omni-modal embeddings. We introduce a curation and synthesis pipeline that generates 24M single-modal and omni-modal conversations.
Paper
Code
Abstract
Advancing machine intelligence requires developing the ability to perceive across multiple modalities, much as humans sense the world. We introduce OmniVinci, an initiative to build a strong, open-source, omni-modal LLM. We carefully study the design choices across model architecture and data curation. For model architecture, we present three key innovations: (i) OmniAlignNet for strengthening alignment between vision and audio embeddings in a shared omni-modal latent space; (ii) Temporal Embedding Grouping for capturing relative temporal alignment between vision and audio signals; and (iii) Constrained Rotary Time Embedding for encoding absolute temporal information in omni-modal embeddings. We introduce a curation and synthesis pipeline that generates 24M single-modal and omni-modal conversations. We find that modalities reinforce one another in both perception and reasoning. Our model outperforms Qwen2.5-Omni with +19.05 on DailyOmni (cross-modal understanding), +1.7 on MMAR (audio), and +3.9 on Video-MME (vision), while using just 0.2T training tokens - a 6 times reduction compared to Qwen2.5-Omni’s 1.2T. We finally demonstrate omni-modal advantages in downstream applications spanning robotics, medical AI, and smart factory.
Advanced MaterialsJournal IF=26.8
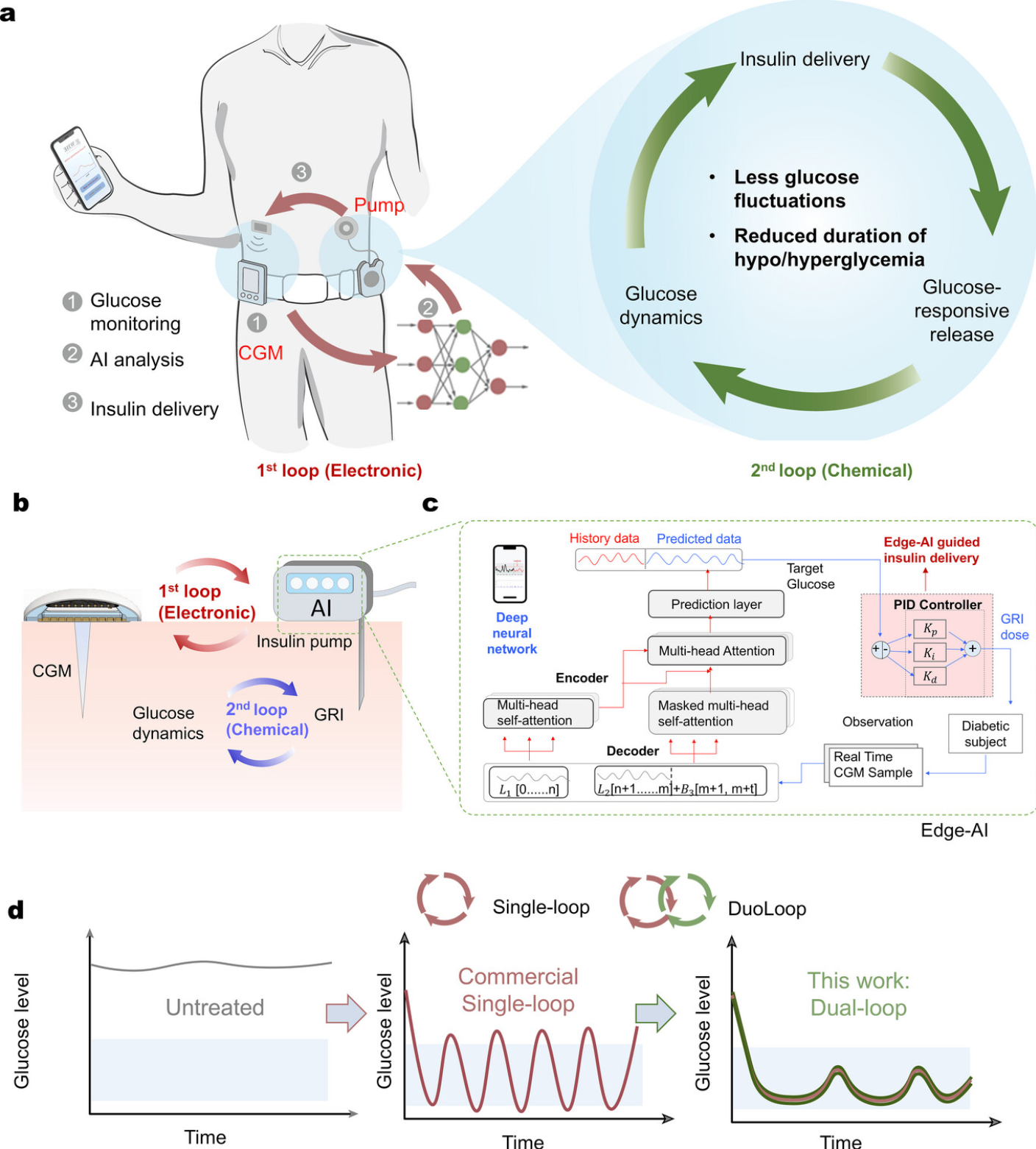
A Wearable, Dual Closed-loop Insulin Delivery System for Precision Diabetes Management
Xuecheng He*, Wei Huang*, Wensheng Lin, Binbin Cui, Xinyu Tian, Jing Bai, Dingyao Liu, Ivo Pang, Hao Huang, Shixian Lin, Jixiang Zhu, Jinqiang Wang, Shiming Zhang
- We have presented a wearable DuoLoop insulin delivery system to address the safety issues associated with traditional single closed-loop ones.
- The 1st closed-loop system automates insulin delivery through wearable CGMs. The 2nd closed-loop system involves the GRI, where the insulin release rate depends on real-time in vivo glucose levels.
- To link the two sections, an AI algorithm was developed by training on extensive glucose data sets, which enables accurate predictions and guides GRI delivery at optimal dosage and timing.
Paper
Code
Abstract
Effective blood glucose management is an increasing demand worldwide. Traditional solutions separate glucose detection and insulin delivery, which is less efficient compared to emerging closed-loop wearable systems controlled by continuous glucose monitors (CGMs). However, CGM-controlled systems raise new safety risks, as false CGMs readings can cause insulin overdose, which results in hypoglycemia and fatal consequences. This work proposes a concept of a dual closed-loop insulin delivery system (DuoLoop) to mitigate the risk issue of CGM-controlled systems. The first closed-loop is automated insulin delivery controlled by CGM. The second closed-loop is the controlled release of glucose-responsive insulin (GRI), whose release rate depends on actual glucose levels. A customized algorithm is trained and embedded into the wearable CGMs for edge computing. The DuoLoop system shows improved safety in preliminary in vivo test (longer normoglycemia durations, 98.82% vs 92.10%), encouraging its deployment toward precision diabetes care.
Neurips 2025
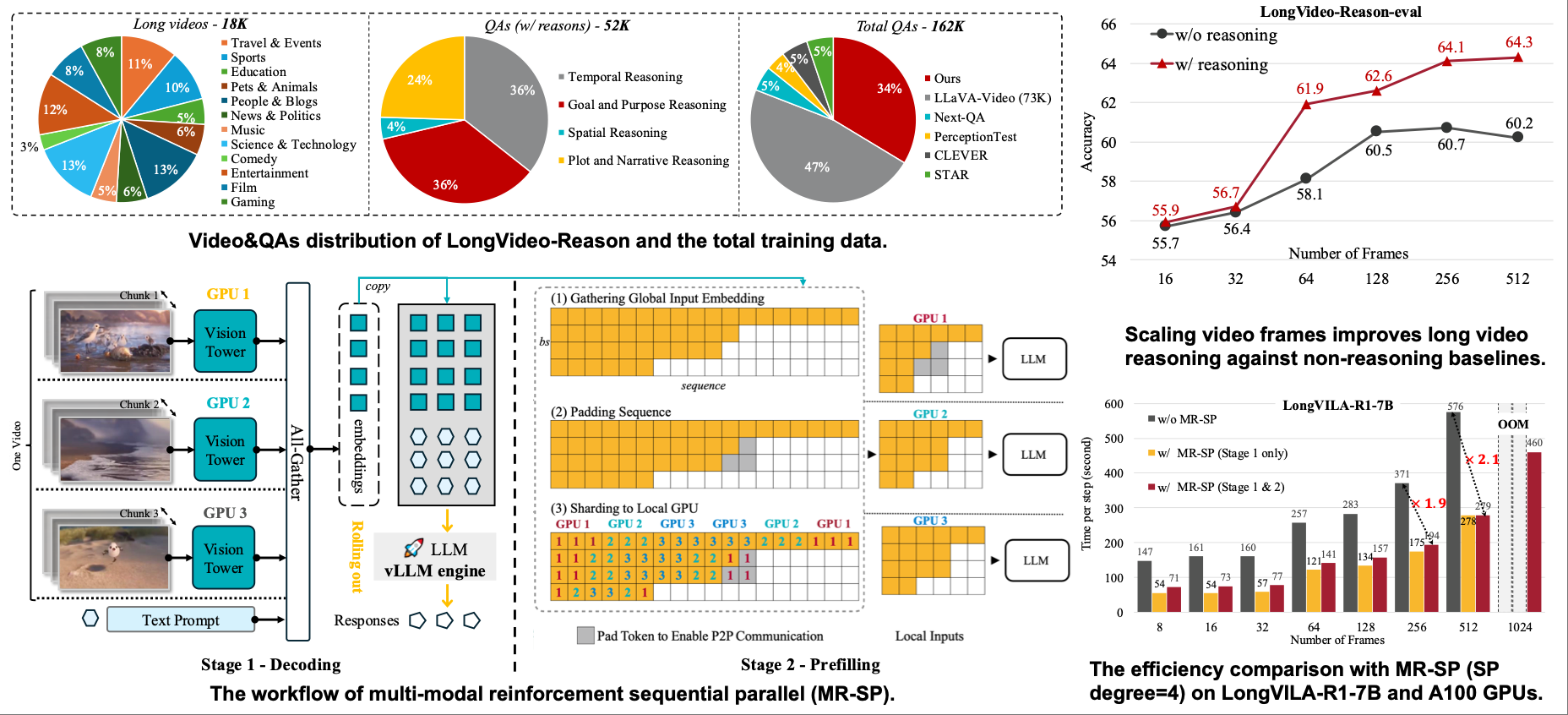
Scaling RL to Long Videos 
Yukang Chen*, Wei Huang*, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu, Hongxu Yin, Yao Lu, Song Han
- MR-SP infrastructure with sequence parallelism and vLLM-based cached-embedding rollouts, enabling up to 8,192 frames, hour-long RL on 8×A100, 2.1× speedup, and strong results (VideoMME 65.1% no subs, 71.1% with subs) via LongVILA-R1-7B.
- Two-stage pipeline combining CoT-SFT and RL to scale reasoning for long-horizon video understanding.
- LongVideo-Reason (104K long-video QA pairs) with high-quality chain-of-thought annotations across diverse domains.
Paper
Code
Abstract
We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 104K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In our experiments, LongVILA-R1-7B achieves strong performance on video benchmarks, reaching 65.1% and 71.1% accuracy on VideoMME without and with subtitles, respectively, and consistently outperforming LongVILA-7B across multiple benchmarks. Moreover, LongVILA-R1-7B supports processing up to 8,192 video frames per video, and configurable FPS settings. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames).
ICML 2025
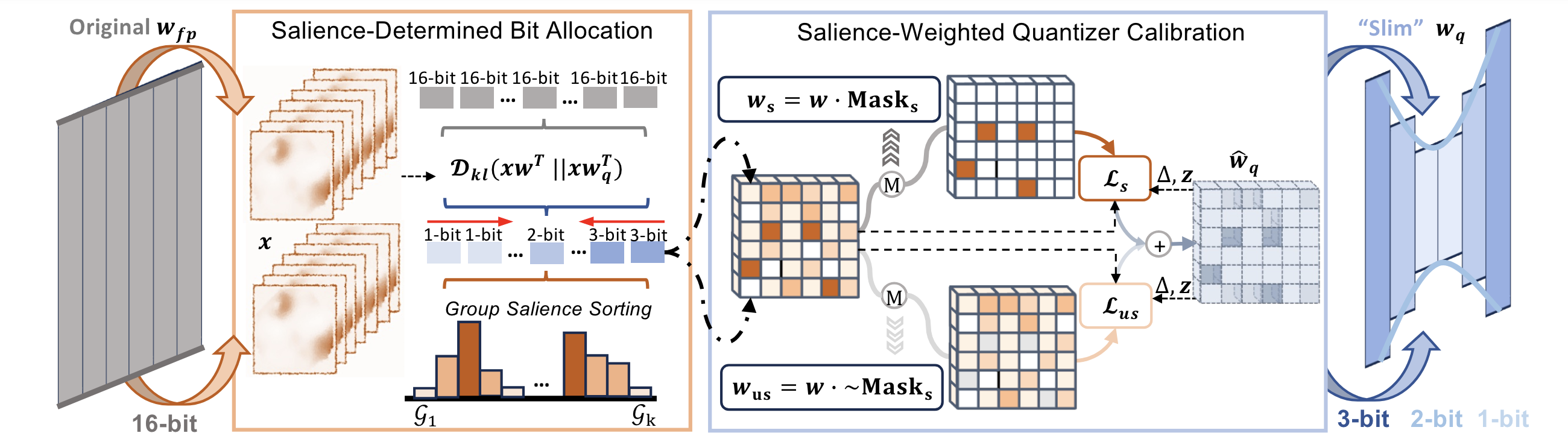
SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models 
Wei Huang, Haotong Qin, Yangdong Liu, Yawei Li, Qinshuo Liu, Xianglong Liu, Luca Benini, Michele Magno, Shiming Zhang, Xiaojuan Qi
- A novel scheme that observes and proves the structure-clustering of salient elements in LLMs weight matrix.
- The first group-wise mixed-precision quantization framework for LLMs.
- Serve as a plug-and-play approach to GPTQ/Omniquant/…, improving the inference-friendly method under low-bit quantization.
Paper
Code
Abstract
Large language models (LLMs) achieve remarkable performance in natural language understanding but require substantial computation and memory resources. Post-training quantization (PTQ) is a powerful compression technique extensively investigated in LLMs. However, existing PTQ methods are still not ideal in terms of accuracy and efficiency, especially with below 4 bit-widths. Standard PTQ methods using group-wise quantization suffer difficulties in quantizing LLMs accurately to such low-bit, but advanced methods remaining high-precision weights element-wisely are hard to realize their theoretical hardware efficiency. This paper presents a Salience-Driven Mixed-Precision Quantization scheme for LLMs, namely SliM-LLM. The scheme exploits the salience distribution of weights to determine optimal bit-width and quantizers for accurate LLM quantization, while aligning bit-width partition to groups for compact memory usage and fast integer inference. Specifically, the proposed SliM-LLM mainly relies on two novel techniques: (1) Salience-Determined Bit Allocation utilizes the clustering characteristics of salience distribution to allocate the bit-widths of each group, increasing the accuracy of quantized LLMs and maintaining the inference efficiency; (2) Salience-Weighted Quantizer Calibration optimizes the parameters of the quantizer by considering the element-wise salience within the group, balancing the maintenance of salient information and minimization of errors. Comprehensive experiments show that SliM-LLM significantly improves the accuracy of LLMs at ultra-low bits, e.g., 2-bit LLaMA-7B achieves a 5.5-times memory-saving than original model on NVIDIA A800 GPUs, and 48% decrease of perplexity compared to the state-of-the-art gradient-free PTQ method. Moreover, SliM-LLM+, which is integrated from the extension of SliM-LLM with gradient-based quantizers, further reduces perplexity by 35.1%.
CVPR 2025 Oral
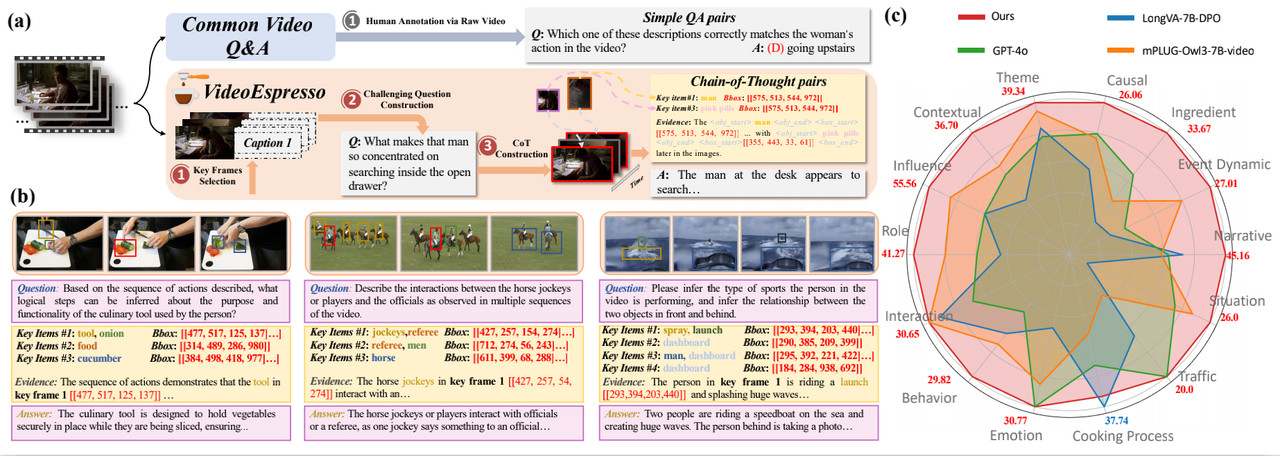
VideoEspresso: A Large-Scale Chain-of-Thought Dataset for Fine-Grained Video Reasoning via Core Frame Selection 
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, Si Liu
- A novel dataset designed to enhance video reasoning by addressing the limitations of existing datasets in terms of scale and granularity.
- We proposed a Hybrid LVLMs Collaboration framework achieving cost-effective and accurate video reasoning, outperforming baseline models on the majority of tasks across our proposed benchmark.
- VideoEspresso sets a new starting point in video reasoning, offering rich annotations that facilitate advanced multimodal understanding.
ICLR 2025
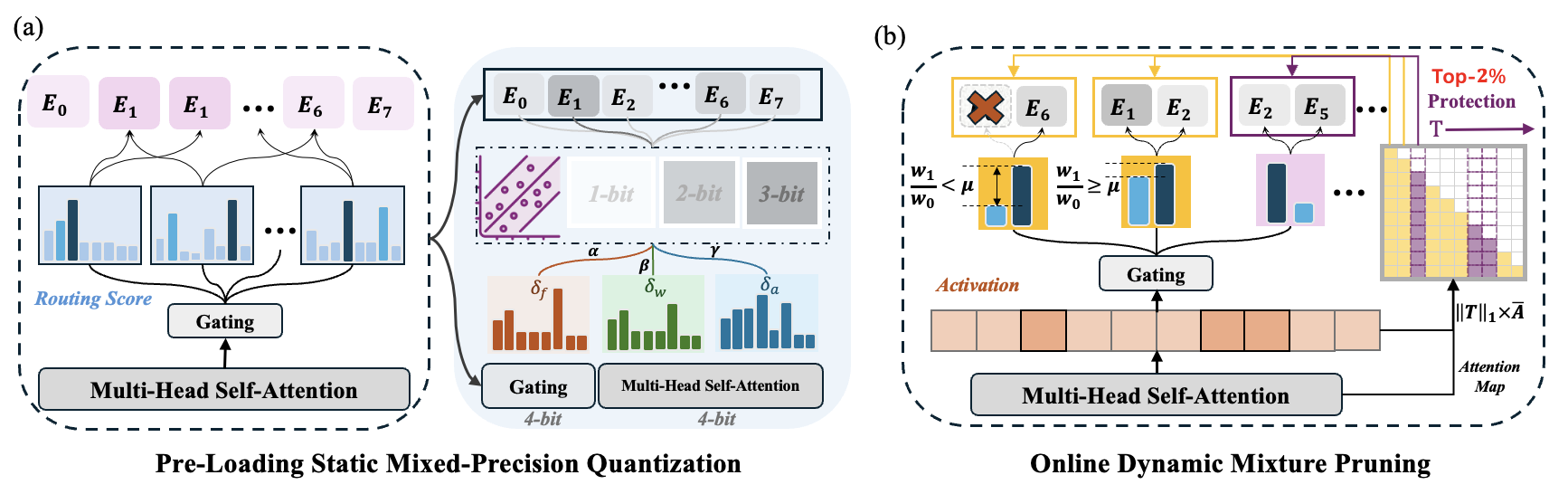
MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More
Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi
- MC-MoE for accurate weight-only quantization (Weight=1.5~2.5bit).
- MC-MoE for efficient online dynamic pruning (additional compression ratio > 10%)
- MC-MoE integrates static quantization and dynamic pruning to collaboratively achieve extreme compression for MoE-LLMs with less accuracy loss, ensuring an optimal trade-off between performance and efficiency.
- For instance, at 2.54 bits, MC-MoE compresses 76.6% of the model, with only a 3.8% average accuracy loss. During dynamic inference, we further reduce activated parameters by 15%, with a performance drop of less than 0.6%.
Paper
Code
Abstract
Mixture-of-Experts large language models (MoE-LLMs) marks a significant step forward of language models, however, they encounter two critical challenges in practice: 1) expert parameters lead to considerable memory consumption and loading latency; and 2) the current activated experts are redundant, as many tokens may only require a single expert. Motivated by these issues, we investigate the MoE-LLMs and make two key observations: a) different experts exhibit varying behaviors on activation reconstruction error, routing scores, and activated frequencies, highlighting their differing importance, and b) not all tokens are equally important -- only a small subset is critical. Building on these insights, we propose MC-MoE, a training-free Mixture-Compressor for MoE-LLMs, which leverages the significance of both experts and tokens to achieve an extreme compression. First, to mitigate storage and loading overheads, we introduce Pre-Loading Mixed-Precision Quantization, which formulates the adaptive bit-width allocation as a Linear Programming problem, where the objective function balances multi-factors reflecting the importance of each expert. Additionally, we develop Online Dynamic Pruning, which identifies important tokens to retain and dynamically select activated experts for other tokens during inference to optimize efficiency while maintaining performance. Our MC-MoE integrates static quantization and dynamic pruning to collaboratively achieve extreme compression for MoE-LLMs with less accuracy loss, ensuring an optimal trade-off between performance and efficiency. Extensive experiments confirm the effectiveness of our approach. For instance, at 2.54 bits, MC-MoE compresses 76.6% of the model, with only a 3.8% average accuracy loss. During dynamic inference, we further reduce activated parameters by 15%, with a performance drop of less than 0.6%.
Visual Intelligence

An Empirical Study of LLaMA3 Quantization: From LLMs to MLLMs 
Wei Huang, Xingyu Zheng, Xudong Ma, Haotong Qin, Chengtao Lv, Hong Chen, Jie Luo, Xiaojuan Qi, Xianglong Liu, Michele Magno
- Explore the performance of LLaMA3 series models under existing post-training quantization and LoRA-finetuning methods.
- Point out the significant performance loss of MLLMs based on LLaMA3 under low-bit post-training quantization.
- Highlights the significant performance gap under low bit-width that needs to be bridged in future developments.
Paper
Code
Abstract
The LLaMA family has become one of the most powerful open-source Large Language Models (LLMs) and the popular LLM backbones of Multimodal Large Language Models (MLLMs), widely applied in Computer Vision (CV) and Natural Language Understanding (NLU) tasks. Notably, LLaMA3 models have recently been released and achieve impressive performance across various with super-large scale pre-training on over 15T tokens of data. Given the wide application of low-bit quantization for LLMs in resource-limited scenarios, we explore LLaMA3's capabilities when quantized to low bit-width. This exploration can potentially unveil new insights and challenges for low-bit quantization of LLaMA3 and other forthcoming LLMs, especially in addressing performance degradation problems that suffer in LLM compression. Specifically, we comprehensively evaluate the 10 existing post-training quantization and LoRA-finetuning methods of LLaMA3 on 1-8 bits and diverse datasets to reveal LLaMA3's low-bit quantization performance. To uncover the capabilities of low-bit quantized MLLM, we assessed the performance of the LLaMA3-based LLaVA-Next-8B model under 2-4 ultra-low bits with post-training quantization methods. Our experimental results indicate that LLaMA3 still suffers non-negligent degradation in linguistic and visual contexts, particularly under ultra-low bit widths. This highlights the significant performance gap under low bit-width that needs to be bridged in future developments. We expect that this empirical study will prove valuable in advancing future models, driving LLMs and MLLMs to achieve higher accuracy at lower bit to enhance practicality.
ICML 2024
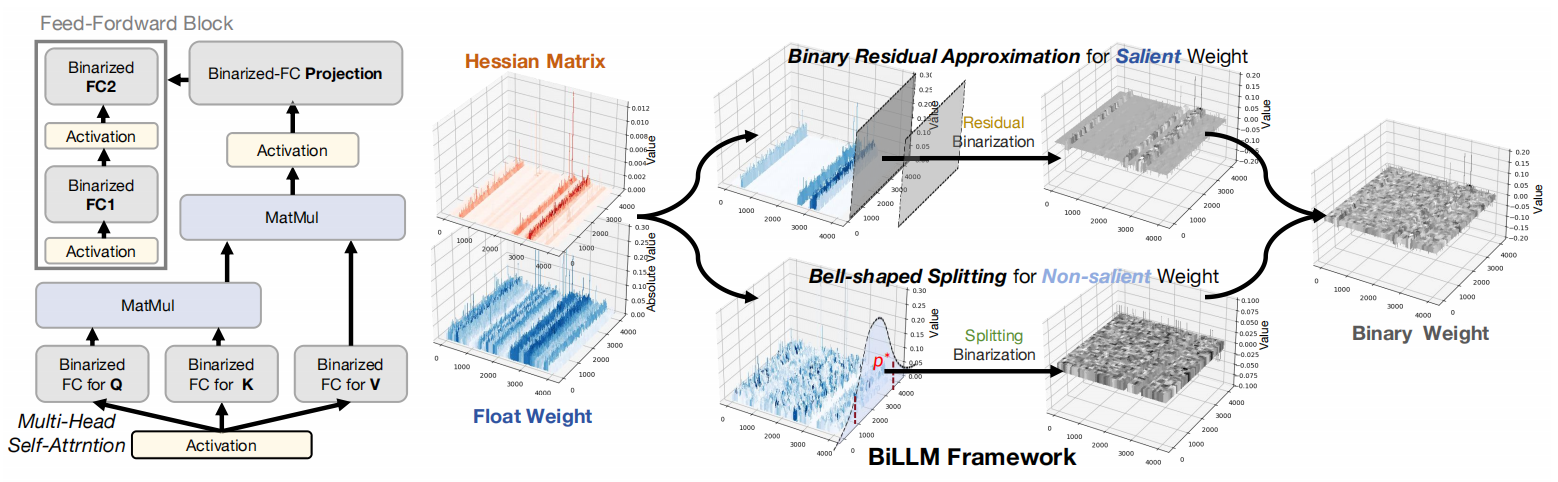
BiLLM: Pushing the Limit of Post-Training Quantization for LLMs 
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi
- Compress LLM weights to as low as 1.08-1.1 bit and exceeds the performance of previous quantization methods at 2-bit or even 3-bit.
- Implements high-performance binary LLM in PTQ mode, efficiently achieving 1bit LLM compression without additional training and backpropagation.
Paper
Code
Abstract
Pretrained large language models (LLMs) exhibit exceptional general language processing capabilities but come with significant demands on memory and computational resources. As a powerful compression technology, binarization can extremely reduce model weights to a mere 1 bit, lowering the expensive computation and memory requirements. However, existing quantization techniques fall short of maintaining LLM performance under ultra-low bit-widths. In response to this challenge, we present BiLLM, a groundbreaking 1-bit post-training quantization scheme tailored for pretrained LLMs. Based on the weight distribution of LLMs, BiLLM first identifies and structurally selects salient weights, and minimizes the compression loss through an effective binary residual approximation strategy. Moreover, considering the bell-shaped distribution of the non-salient weights, we propose an optimal splitting search to group and binarize them accurately. BiLLM achieving for the first time high-accuracy inference (e.g. 8.41 perplexity on LLaMA2-70B) with only 1.08-bit weights across various LLMs families and evaluation metrics, outperforms SOTA quantization methods of LLM by significant margins. Moreover, BiLLM enables the binarization process of the LLM with 7 billion weights within 0.5 hours on a single GPU, demonstrating satisfactory time efficiency.
Arxiv
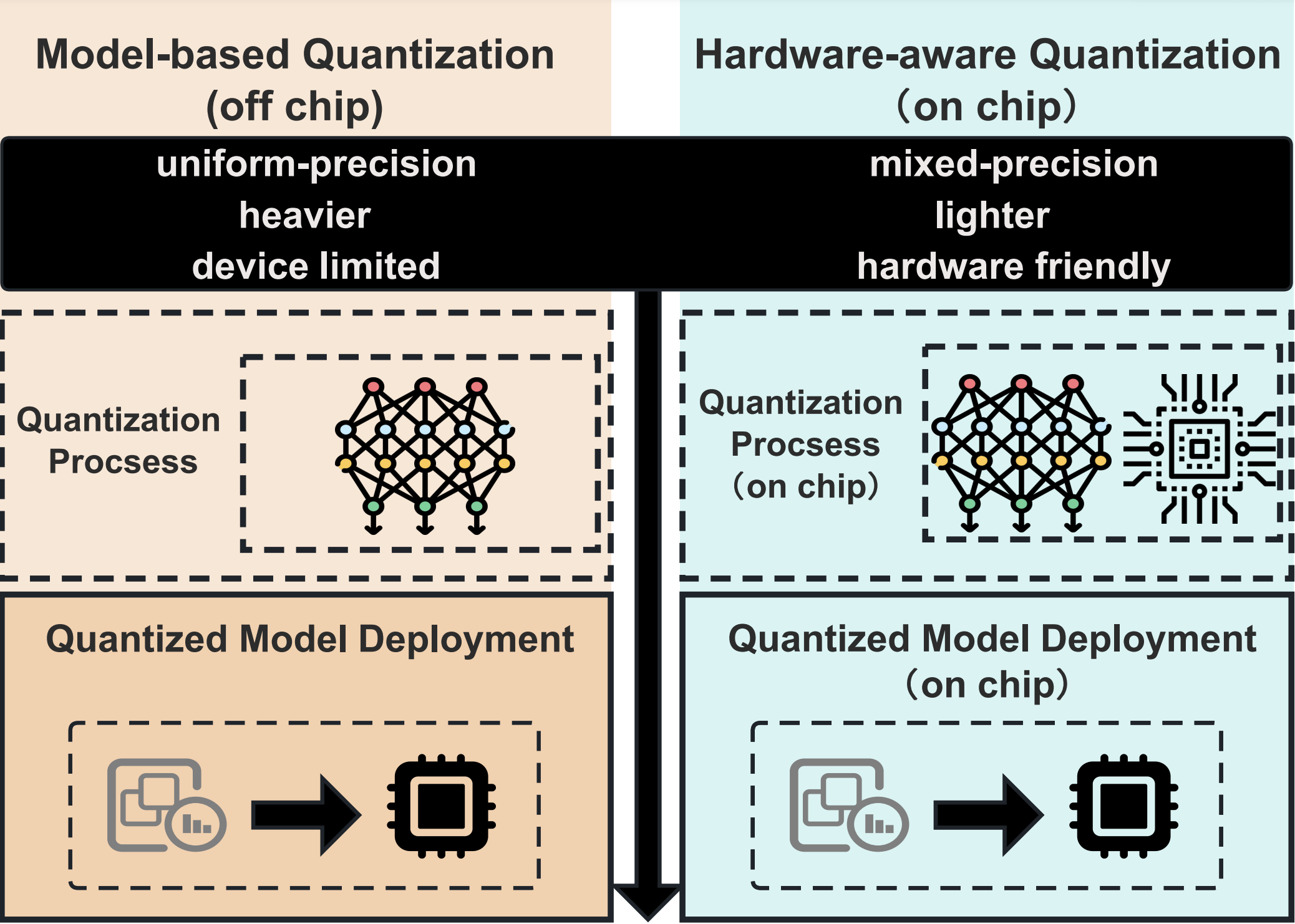
On-Chip Hardware-Aware Quantization for Mixed Precision Neural Networks
Wei Huang, Haotong Qin, Yangdong Liu, Jingzhuo Liang, Yulun Zhang, Ying Li, Xianglong Liu
- Combine IP-core-level chip runtime clock and power awareness with network sensitivity, achieving a better balance of computational efficiency and accuracy on edge devices.
- Allow target networks to be compressed and deployed with high accuracy on edge chips with limited computational resources and ultra-low power consumption.
- Efficiently perform online quantization and optimization without additional devices or data access.
Paper
Abstract
Low-bit quantization emerges as one of the most promising compression approaches for deploying deep neural networks on edge devices. Mixed-precision quantization leverages a mixture of bit-widths to unleash the accuracy and efficiency potential of quantized models. However, existing mixed-precision quantization methods rely on simulations in high-performance devices to achieve accuracy and efficiency trade-offs in immense search spaces. This leads to a non-negligible gap between the estimated efficiency metrics and the actual hardware that makes quantized models far away from the optimal accuracy and efficiency, and also causes the quantization process to rely on additional high-performance devices. In this paper, we propose an On-Chip Hardware-Aware Quantization (OHQ) framework, performing hardware-aware mixed-precision quantization on deployed edge devices to achieve accurate and efficient computing. Specifically, for efficiency metrics, we built an On-Chip Quantization Aware pipeline, which allows the quantization process to perceive the actual hardware efficiency of the quantization operator and avoid optimization errors caused by inaccurate simulation. For accuracy metrics, we propose Mask-Guided Quantization Estimation technology to effectively estimate the accuracy impact of operators in the on-chip scenario, getting rid of the dependence of the quantization process on high computing power. By synthesizing insights from quantized models and hardware through linear optimization, we can obtain optimized bit-width configurations to achieve outstanding performance on accuracy and efficiency. We evaluate inference accuracy and acceleration with quantization for various architectures and compression ratios on hardware. OHQ achieves 70% and 73% accuracy for ResNet-18 and MobileNetV3, respectively, and can reduce latency by 15~30% compared to INT8 on real deployment.
📖 Educations
- 2023.09 - (now), Ph.D. Student in Department of Electrical Electronic Engineering, The University of HongKong.
- 2019.09 - 2023.06, B.Eng. in Computer Science, School of Computer Science and Engineering, Beihang University.
🗒️ Academic Services
- Conference Reviewer: ICLR, Neurips, ICML, ECCV, CVPR, ICCV
- Journal Reviewer: IEEE TPAMI, Neural Networks.
- Program Committee member for Practical Deep Learning Workshop, IEEE CAI 2024.
🎖 Honors and Awards
-2023 Outstanding Graduate, Beihang University.
-2023 Outstanding Project of the 16th National College Student Innovation and Entrepreneurship Competition, China.
-2022 Outstanding Project of the 15th National College Student Innovation and Entrepreneurship Competition, China.
💻 Internships & Teaching Services
- 2026.03 - Now, LLM Research Intern, NVIDIA.
- 2025.06 - 2026.02, Multimodal Large Language Model Intern, NVIDIA.
- 2022.09 - 2023.01, AI algorithm internship on model inference acceleration, Enflame, China.
- 2022.08 - 2023.01, TA for Frontiers in Artificial Intelligence, Beihang University.
- 2022.08 - 2023.01, TA for Computer Hardware Basics, the head of TA team, Beihang University.
- 2021.08 - 2022.01, TA for Computer Hardware Basics, the head of TA team, Beihang University.
- 2021.03 - 2021.06, TA for Discrete Mathematics, the head of TA team, Beihang University.

